
As a data science startup, we were thrilled to partner with a major services provider in the food and beverage (F&B) industry. Our mission? To build a predictive maintenance model using LLMs that could accurately forecast equipment failures and maintenance requirements in the near future – allowing the service provider to streamline their operations. Initially, we focused on leveraging the structured data at our disposal. We crafted a classical machine learning model, carefully engineering features from historical maintenance records, equipment specifications, and external factors like weather, regional events, and their impact on F&B consumption. While this model had great performance metrics, we were determined to push the boundaries further. Our attention turned to the treasure trove of unstructured text data nestled within service technicians’ notes to enhance our predictive maintenance model using LLMs. Could these notes hold the key to unlocking even greater predictive power?
That’s when Large Language Models (LLMs) entered the scene. By now, we’ve all interacted with LLMs in some capacity. We have witnessed their tremendous prowess at generating new text, images and even videos. However, LLMs extend far beyond just text generation; they play a crucial role in building predictive models by generating text embeddings.
LLMs are deep learning algorithms trained on massive datasets of text and code, allowing them to understand and generate human-quality text. A key capability of LLMs is their ability to generate “embeddings,” which are essentially numerical representations of words, sentences, or even entire paragraphs. Imagine you have two sentences: “Taylor Swift’s concert was a resounding success” and “Arsenal dominate Chelsea in a five-star performance”. While these sentences differ greatly in content, LLMs can convert them into numerical vectors (embeddings) that capture their underlying meaning. These embeddings would highlight the “positive sentiment” shared by both sentences, albeit in different contexts—one musical, the other athletic.
These embeddings become incredibly powerful tools for analysing unstructured text data, identifying patterns, and uncovering hidden relationships. Since the embeddings are just numbers, they can be fed into classic machine learning models like any other features and could allow the model to derive insights from the text data.
Classical Approach: Text Embeddings and Their Limitations in Predictive Maintenance Model Using LLMs
Our initial approach involved using pre-trained LLMs to generate embeddings for the client’s service notes. These embeddings, often hundreds of numbers long, captured semantic information about the text. We then fed these embeddings into a predictive model along with other relevant features to estimate the likelihood of high maintenance needs at each location.
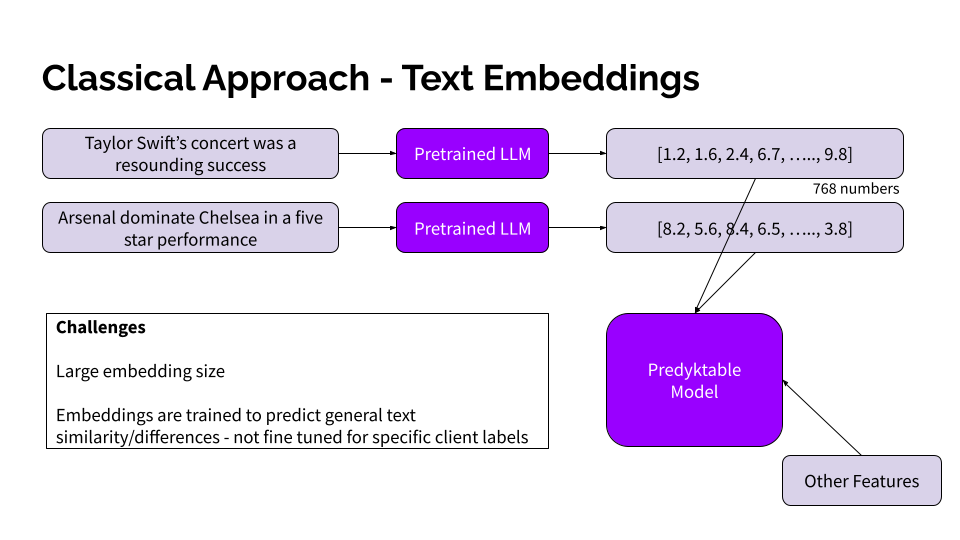
While conceptually sound, this approach faced challenges:
- Large Embedding Size: The high dimensionality of the embeddings increased model complexity and computational costs.
- Not Specific to Client Data: Pre-trained LLM embeddings are optimised for general language understanding and might not accurately capture the nuances specific to our client’s industry and operational context. In the above example, the embeddings haven’t been specifically trained to relate text to high maintenance needs in the F&B industry.
Enter Fine-Tuning: Tailoring LLMs for Specific Tasks in Our Predictive Maintenance Model Using LLMs
Fine-tuning offers a solution to the above challenges by further training an already powerful LLM on a specific dataset and task, such as classifying F&B service notes. The pre-trained LLM is trained using the client’s specific data. In this case, it’s the service technicians’ and agents’ text notes along with their corresponding maintenance outcomes (how many hours of maintenance tasks are needed in the future). This training aligns the model’s understanding of language directly with the client’s terminologies and context.
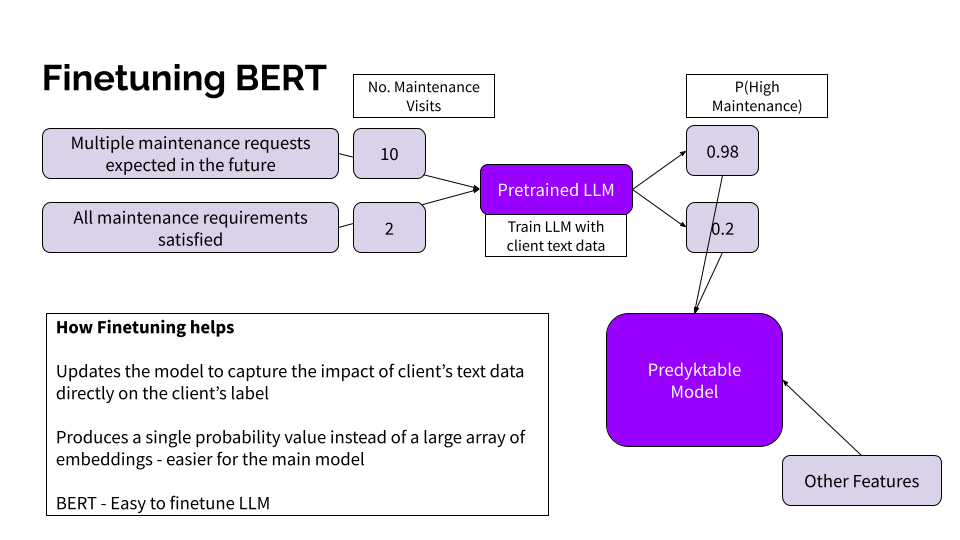
Challenges with the Client Data
All Large Language Models (LLMs) have a limit on the number of words (tokens) they can process as input. Larger LLMs, like Google Palm, can handle more tokens but are harder to fine-tune due to their size. Smaller LLMs, like BERT, can process fewer tokens but are easier to fine-tune with new data.
The client data we were working with was enormous—it included all service provider notes from across a geographical area for the past week. The following image shows a sample of this data:

This data presented us with two challenges:
- The input data size was quite large and could not directly be used as an input to easy-to-finetune LLMs like BERT.
- The data seemed quite gibberish and it seemed quite improbable that directly finetuning an LLM using this data would have any value.
In the following sections, we will explain the two-stage process used to address these issues.
A Two-Step Solution: Summarisation and Fine-Tuning with BERT
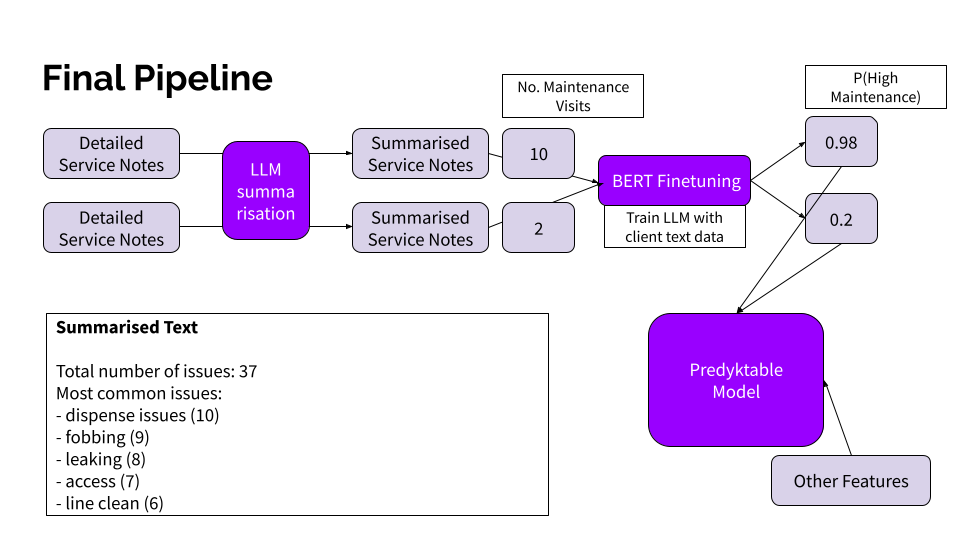
Step 1: Summarisation: We utilised a large LLM like Google Palm to summarise the lengthy and detailed service notes into concise, information-rich summaries. These summaries focused on extracting the total number of maintenance issues and different types of issues faced by the outlets in the area, significantly reducing the text volume without sacrificing crucial information.

Step 2: Fine-Tuning BERT: Summarisation created a succinct view of the different types of issues faced in a particular area in the past week. This text was extremely relevant for predicting the expected number of maintenance requests in the future. The second step involved capturing this dependency by finetuning a BERT model. BERT (Bidirectional Encoder Representations from Transformers) is a versatile and powerful language model that is relatively easy to train on new data due to its small size.
The overall process is captured in the following diagram:
Promising Results
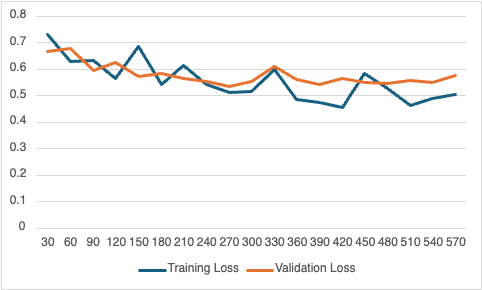
We observed a strong correlation of 0.65 between the P(High Maintenance Needs) score generated by BERT and the actual number of maintenance visits at each location. This indicated that the BERT model, after fine-tuning, was successfully learning from the client’s service note data and translating it into meaningful predictions. The plot below illustrates the reduction in both training and validation loss over epochs (iterations) during the fine-tuning process, highlighting the effectiveness of our approach in making the BERT model better at its predictive task.
This solution offered a more precise and efficient approach for leveraging unstructured text data. By fine-tuning BERT, we successfully bridged the gap between general language understanding and our client’s specific business context. This project highlights how a predictive maintenance model using LLMs can effectively leverage unstructured data sources, like free-text call notes, can be harnessed to improve field service operations and deliver a superior customer experience.
Learn more about how a predictive maintenance model using LLMs can transform your business operations – Contact us today!